
The basics that you need to know about protobuf in a a single post
Why Protobuf?
- Fully type safe.
- Data is auto compressed which reduces cpu and network bandwidth usage.
- Provides backward and forward compatibility.
- 3-10x smaller, 20-100x faster than xml.
- Provides ability to auto-generate client code in multiple languages, schema(.proto file) is used to generate code and read the data.
- RPC frameworks like gRPC uses Protocol Buffers by default, which provides much better performance than JSON.
- Easy to learn.
Disadvantages
- Support for some languages might be lacking(most mainstream languages are fine).
- Cant open the serialised data with a text editor.
- Every field in a Protobuf message is optional and has a default value, it is impossible to differentiate a field that is missing in a protocol buffer from one that was assigned with the default value. ex; Int is defaulted to Zero, strings and arrays are defaulted to empty!
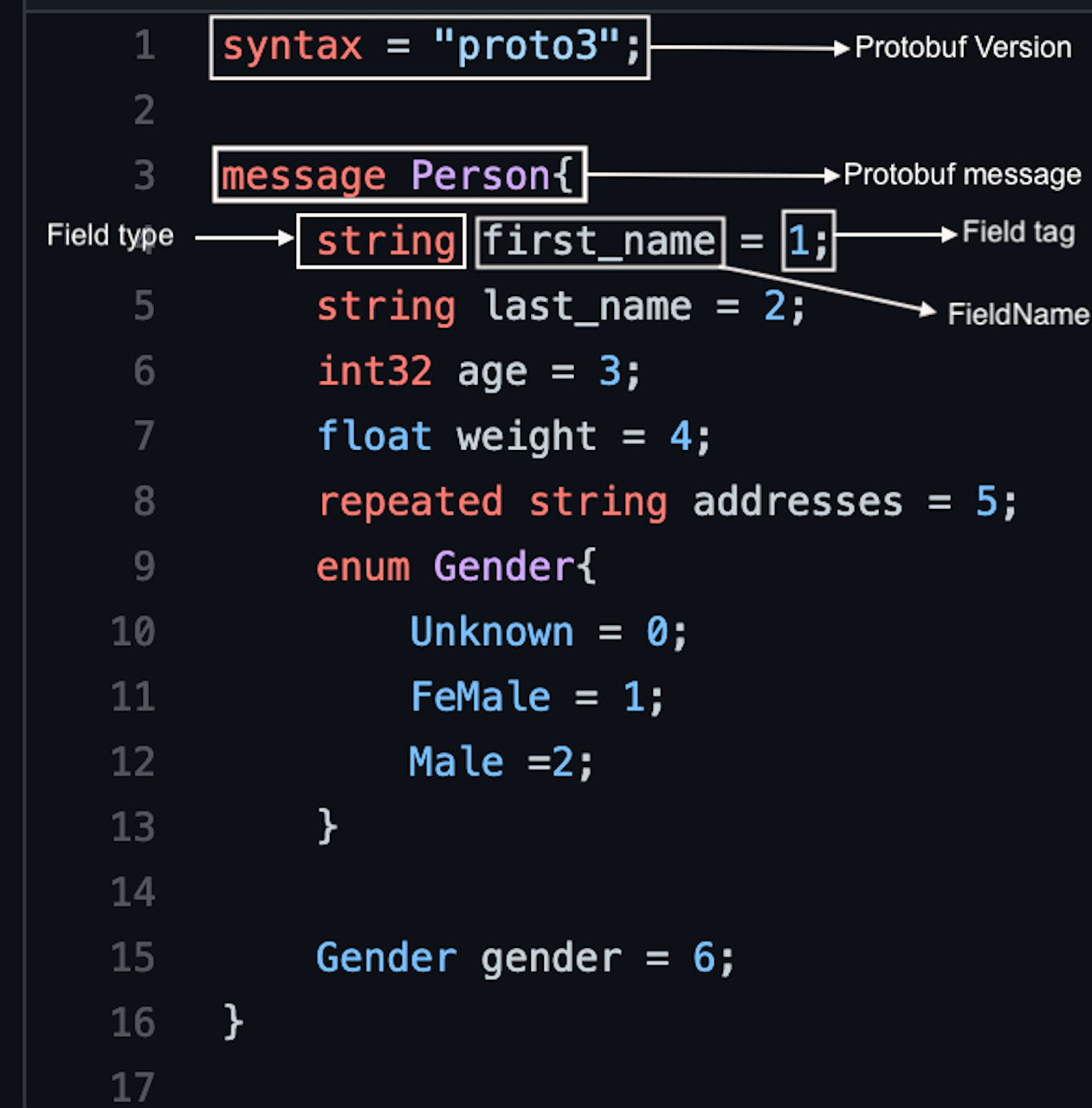
What is a .Proto file?
Protocol buffers has it's own style guide and it is important to follow that, as the code generation depends on it.
Proto compiler converts the .proto file into a language specific implementation, you can find the data types supported by protocol buffers and it's language specific conversions here
Here is an example of generating java code from proto file, you can specify the language options that you like.
protoc -I=proto --java_out==java proto/simple_proto.proto
This command takes a .proto file named simple_proto.proto which is located in directory named proto and converts into SimpleProto.java and puts it in another directory called java, the generated java file is quite verbose, you can see it here
Working with Protobuf
Field tags/Field numbers:
- Field tags uniquely identify a field in protobuf, it has to be an unique integer.
- Smallest tag is 1, largest is 2^29-1.
- Remember tag number 1-15 use 1 byte in space use them for frequently populated fields, tags from 16-2047 takes 2 bytes and so on.
- You can't use the tags from 19,000-19,999 these are the tags reserved by google.
- Field tags should never be changed once your message type is in use.
- You cannot use any previously reserved field numbers.
Default values
If the value is not specified for any field in protobuf it always gets a default value
| Data Type | Default value |
|---|---|
| bool | false |
| number | 0 |
| string | empty string |
| bytes | empty bytes |
| enum | first value |
| repeated | empty list |
Advanced data types
oneof:
- oneof fields are like regular fields except all the fields in a oneof share memory, and at most one field can be set at the same time. Setting any member of the oneof automatically clears all the other members
- If the parser encounters multiple members of the same oneof on the wire, only the last member seen is used in the parsed message.
2. Map
3. Timestamp
Represents a point in time independent of any time zone or local calendar, contains seconds and nano seconds .
4. Duration
Represents timespan between two timestamps, contains seconds and nano seconds.
Rules for protobuf schema evolution
- Never change the field tags for any existing fields.
- If you add new fields all clients using old .protofile will just ignore the new field.
- Like wise if a new code gets old data, default values will be used.
- Fields can be removed but the removed tag number should never be reused, adding obsolete or reserved is the better way to deprecate the fields.
- Renaming of fields is allowed, Protobuf uses key tags for serializing / deserializing.
- some compatible data type changes is allowed, use it with extreme precaution
- Never remove any reserved tags.
- when removing a field always reserve both field tag and field name, reserve tags to prevent new fields from using it, reserve names to prevent code bugs.
